
AI Driven Analytics find the right instance for every workload.
Vendor
Densify
Company Website
Fully Automate Kubernetes Resource Optimization
Eliminate human guesswork and manual effort
Slash Cost, Improve Reliability and Spend Less Time Managing
Legitimate understanding of your full stack and how each element impacts the other
Many solutions claim to be able to optimize but most will just make a mess because they don’t truly understand these interrelationships.
See past noise and risky changes to get to what matters: realizable gains
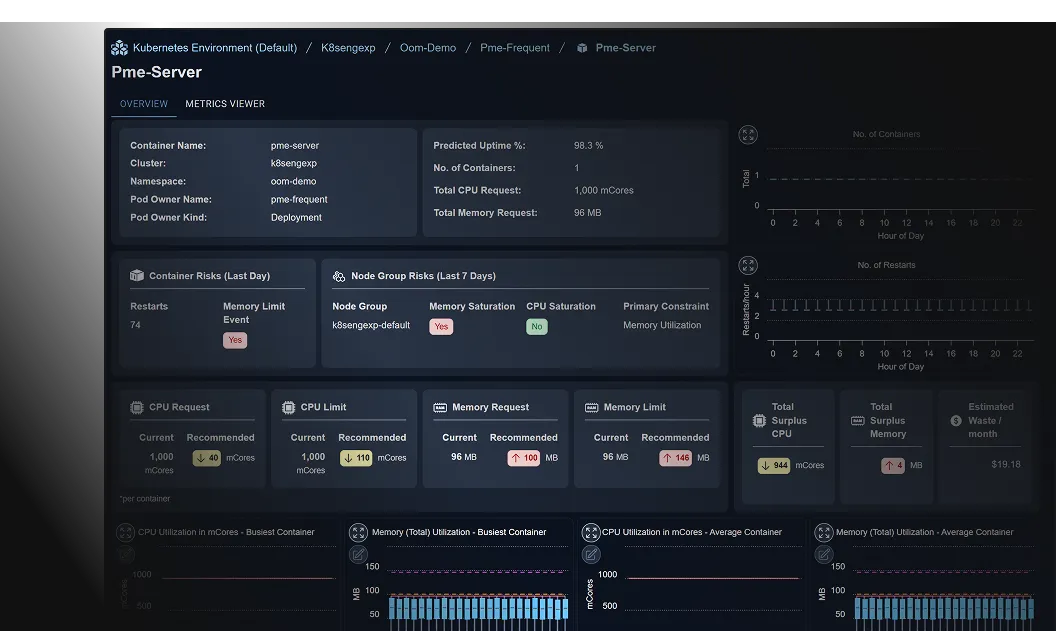
See top ranked risk and waste issues. The analytics are meticulous and high trust. You can automate recommended changes safely.
Automate using the most trustworthy recommendations on the market
Use Kubex’s Mutating Admission Controller or connect to the frameworks that you use already.
Easily share findings with others
Deep links direct to any data element or page in Kubex so you can direct attention to anything you want to share.
Optimize the Cost of GPU-Based Resources
Optimize GPU-Based K8s Nodes
Constantly optimize the GPU instance types underpinning node groups:
- Combine container optimization with unique cloud-level optimization to ensure the node types are optimal.
- “Full stack” approach models requested resources for AI/ML containers to simulate resource requirements at the node-level.
- Modeling of NVIDIA GPU types and policy-based control over which to use and what GPU-to-Memory ratios are optimal.
Track Node-Level GPU and GPU Memory Utilization
Track the aggregate node-level utilization of AI/ML workloads:
- Model the combined impact of all GPU-enabled and AI/ML containers scheduled on each node.
- Identify constraints and saturation points that can impact LLM performance, including factors impacting training duration and inference response time.
- Determine the effectiveness of GPU slicing algorithms, including time slicing, Multi-instance GPU (MIG), and.
- Multi-Process Service (MPS).
The devil is in the detail that other products just don’t see
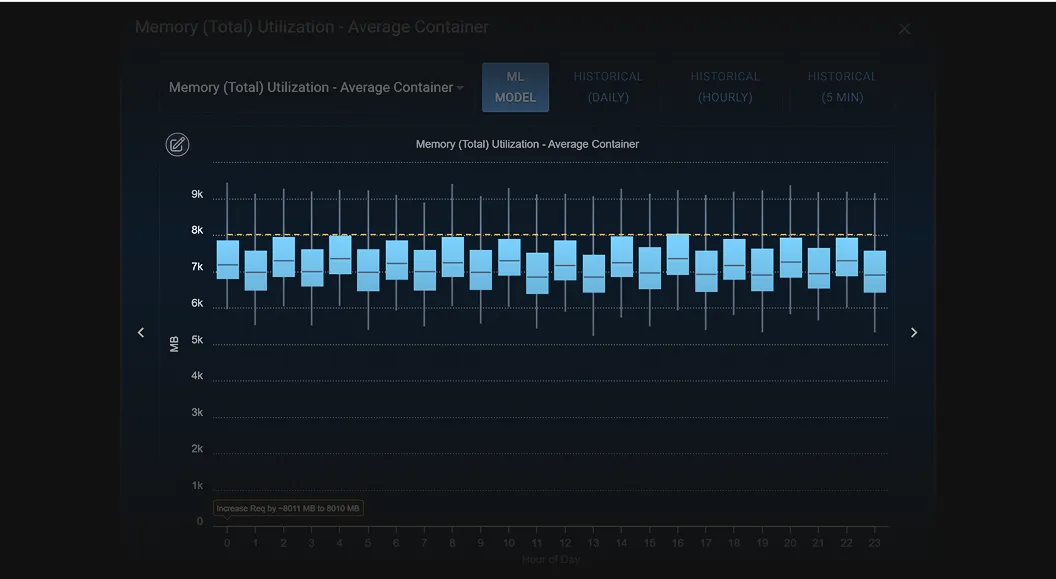
Machine learning of hourly patterns
Under every recommendation surfaced is a machine learned pattern that you can see by drilling in.
Historical daily patterns
Kubex has detected memory limit events and restarts and recommends increasing memory limits.