
Reliable data pipelines made easy.
Vendor
Databricks
Company Website
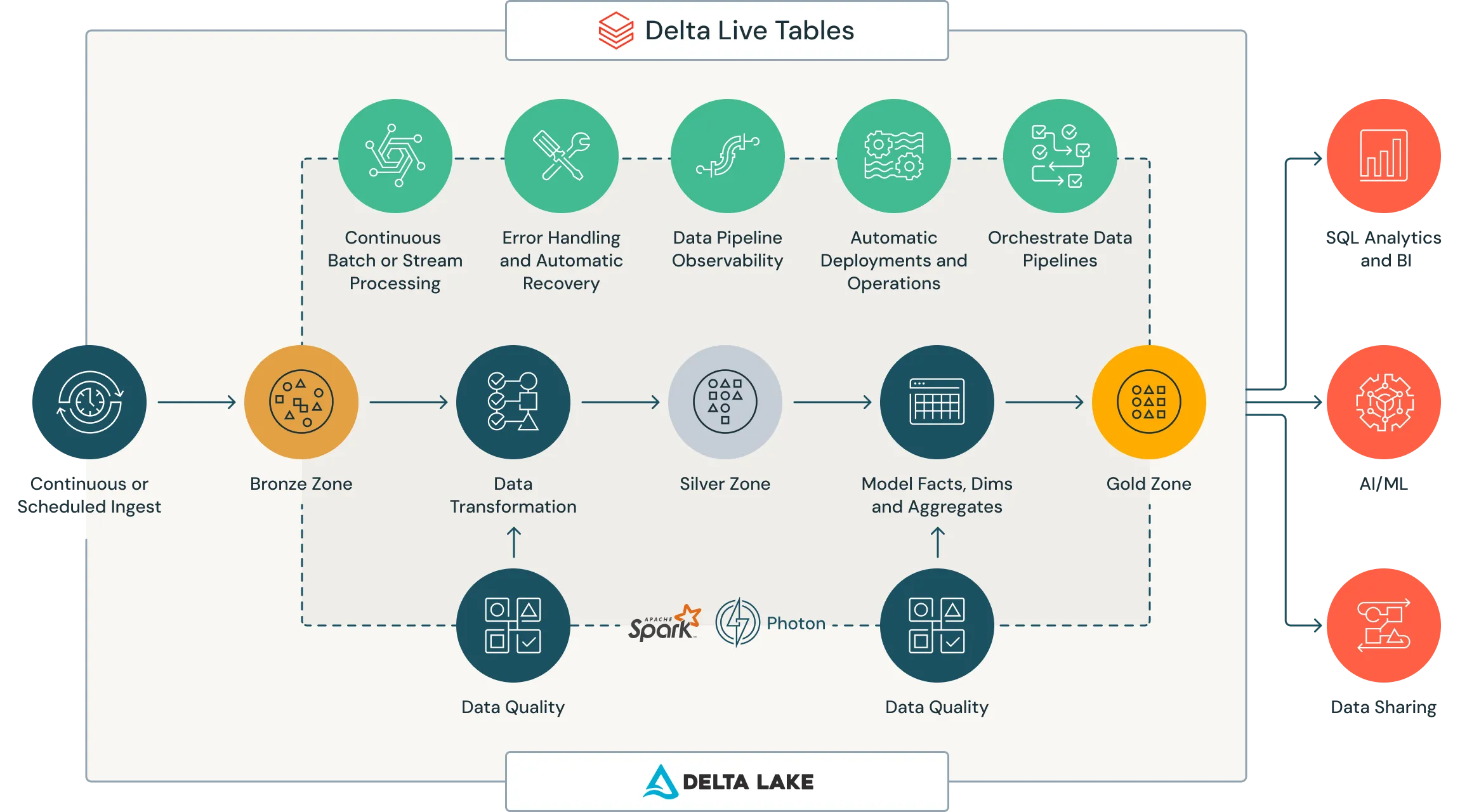
Delta Live Tables (DLT) is a declarative ETL framework for the Databricks Data Intelligence Platform that helps data teams simplify streaming and batch ETL cost-effectively. Simply define the transformations to perform on your data and let DLT pipelines automatically manage task orchestration, cluster management, monitoring, data quality and error handling.
Benefits
Efficient data ingestion
Building production-ready ETL pipelines begins with ingestion. DLT powers easy, efficient ingestion for your entire team — from data engineers and Python developers to data scientists and SQL analysts. With DLT, load data from any data source supported by Apache Spark on Databricks.
- Use Auto Loader and streaming tables to incrementally land data into the Bronze layer for DLT pipelines or Databricks SQL queries
- Ingest from cloud storage, message buses and external systems
- Use change data capture (CDC) in DLT to update tables based on changes in source data
Intelligent, cost-effective data transformation
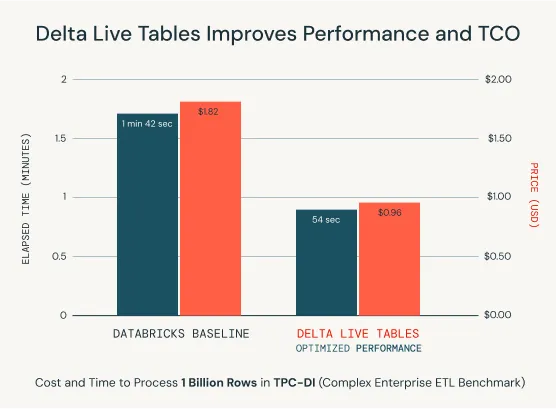
From just a few lines of code, DLT determines the most efficient way to build and execute your streaming or batch data pipelines, optimizing for price/performance (nearly 4x Databricks baseline) while minimizing complexity.
- Instantly implement a streamlined medallion architecture with streaming tables and materialized views
- Optimize data quality for maximum business value with features like expectations
- Refresh pipelines in continuous or triggered mode to fit your data freshness needs
Simple pipeline setup and maintenance
DLT pipelines simplify ETL development by automating away virtually all the inherent operational complexity. With DLT pipelines, engineers can focus on delivering high-quality data rather than operating and maintaining pipelines. DLT automatically handles:
- Task orchestration
- CI/CD and version control
- Autoscaling compute infrastructure for cost savings
- Monitoring via metrics in the event log
- Error handling and failure recovery
Next-gen stream processing engine
Spark Structured Streaming is the core technology that unlocks streaming DLT pipelines, providing a unified API for batch and stream processing. DLT pipelines leverage the inherent subsecond latency of Spark Structured Streaming, and record-breaking price/performance. Although you can manually build your own performant streaming pipelines with Spark Structured Streaming, DLT pipelines may provide faster time to value, better ongoing development velocity, and lower TCO because of the operational overhead they automatically manage.
Unified data governance and storage
Running DLT pipelines on Databricks means you benefit from the foundational components of the Data Intelligence Platform built on lakehouse architecture — Unity Catalog and Delta Lake. Your raw data is optimized with Delta Lake, the only open source storage framework designed from the ground up for both streaming and batch data. Unity Catalog gives you fine-grained, integrated governance for all your data and AI assets with one consistent model to discover, access and share data across clouds. Unity Catalog also provides native support for Delta Sharing, the industry’s first open protocol for simple and secure data sharing with other organizations.