
Speed up your development with a runtime environment built to scrape, unlock, and scale web data collection.
Vendor
Bright Data
Company Website

What are Serverless Functions
Serverless Functions are a fully hosted cloud solution designed for developers to build fast and scalable scrapers in a JavaScript coding environment. Built on Bright Data’s unblocking proxy solution, the IDE includes ready-made functions and code templates from major websites – reducing development time and ensuring easy scaling.
Build a winning scraper
73+
- Ready-made JavaScript functions 38K+
- Scrapers built by our customers 195
- Countries with proxy endpoints
Develop more, maintain less
Reduce mean time to deliver by using ready-made JavaScript functions and online IDE to build your web scrapers at scale.
Features
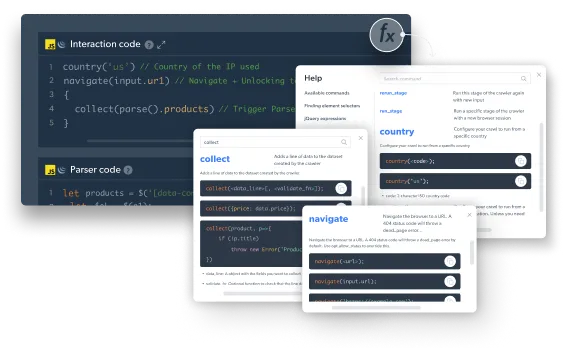
Scraping-ready functions
Choose from 70+ scraping-proof code templates and implement custom changes that match your specific use.
Online dev environment
Fully-hosted IDE to allow scalable CI/CD processes.
Embedded debugger
Review logs and integrate with Chrome DevTools to nail down root cause analysis.
JavaScript browser interaction
Control browser actions using JavaScript protocols.
Built-in parser
Write your parsers in cheerio and run live previews to see what data it produced.
Observability dashboard
Track, measure and compare between your scrapers and jobs in a single dashboard.
Auto-scaling infrastructure
Invest-less in hardware and software maintenance and shift your compute processes into the cloud.
Proxy auto-pilot
Run your scrapers as a real-user via any geo-location with built-in fingerprinting, automated retries, CAPTCHA solving, and more.
Integration
Trigger scrapers on a schedule or by API and connect to numerous 3rd party service providers.
Data collection process
Crawl website
Uncover an entire list and hierarchy of website URLs matching your need in a target website. Use ready made functions for the site search and clicking the categories menu, such as:
- Data extraction from lazy loading search (load_more(), capture_graphql())
- Pagination functions for product discovery
- Support pushing new pages to the queue for parallel scraping by using rerun_stage() or next_stage()
Scrape data
Build a scraper for any page, using fixed URLs, or dynamic URLs using an API or straight from the discovery phase. Leverage the following functions to build a web scraper faster:
- HTML parsing (in cheerio)
- Capture browser network calls
- Prebuilt tools for GraphQL APIs
- Scrape the website JSON APIs
Validate data
Run tests to ensure you get the data you expect
- Define the schema of how you want to receive the data
- Custom validation code to show that the data is in the right format
- Data can include JSON, media files, and browser screenshots
Deliver data
Deliver the data via all the popular storage destinations:
- API
- Amazon S3
- Webhook
- Microsoft Azure
- Google Cloud PubSub
- SFTP